本周沉迷《塞尔达传说:王国之泪》,无心顾及其他,博客鸽了。 塞尔达就是天!永远能让我充满好奇心跟探索的欲望,让我重拾最本质的快乐,体验一段属于自己的冒险。能在有生之年玩到塞尔达太幸福了!
标签: 周更挑战
-
Vol.23 塞尔达就是天!

-
Vol.22 《大浴女》是复杂人性的真实记录
终于读完机核朋友推荐的铁凝的《大浴女》,看到结尾心情确实有些沉重。我很羡慕她们在最后可以勇敢又坦然地接纳自己,说出自己内心最深处伤痕。我经常跟别人说真正的放下就是微笑面对曾经恐惧逃避的事务,但我自己做不到,我还是无法接纳跟面对自己的原生家庭,我还在逃避。 书中对于人性的描写丝毫不忌讳,我真的感觉这才...

-
Vol.21 《灌篮高手》不是我的青春但依旧喜欢
假期第一天没有出门,想着再不做点什么浪费我美好的假期,于是看完《读库2301》之后临时约 22 点场,出门那一刻心情非常愉悦,今天焦虑抑郁愤怒的情绪消失殆尽。 这是我今年看过最喜欢的一部电影,比马里奥大电影还喜欢。看之前我还担心因为没有看过动画难以融入剧情,事实证明是我多虑了。湘北五虎每个人性格特点...

-
Vol.20 企业生产环境当中 spark 任务提交的几种方式
spark 任务提交 4 种方式 spark 任务提交的方式通常有 4 种:spark-shell、spark-sql 、Thriftserver 服务、spark-submit。 spark-shell spark-shell 是 Spark 自带的交互式 Shell 程序,方便用户进行交互式编程...

-
Vol.19 最好的同事这周离职了
这周坐我旁边的最好的同事离职了,工作 5 年,这个同事是我职场生涯当中关系最好的朋友。从我入职开始她就坐我旁边,手把手指导我度过新人期,可以说我在公司的所有知识跟技能都是她传授的。有些同事只是同事,有些是可以成为一生的朋友。刚刚到这家公司的时候,我是一个孤傲内向的钢铁直男,工作上粗心大意经常小错误,...

-
Vol.18 Redis 学习笔记
基本介绍 - 定义 - 基于内存的分布式的NoSQL数据库 - 设计 - 所有数据存储在内存中 - 内存数据同步磁盘,实现持久化 - 功能 - 提供高性能高并发的数据存储, 对外提供读写 - 主要用于数据库存储、数据缓存和消息中间件 - 特点 - 1.基于C语言开发,读写更快 - 2.基于内存实现数...

-
Vol.17 分享下定制的 splatoon3 铭牌跟斜跨包
非常喜欢,感觉有点羞耻怎么回事,在街上碰见我千万别打招呼 😂 铭牌跟鱼蛋徽章都是@贴牌小铺🦑冷店长,斜挎包是@tomtoc-official 定制的 为了塞尔达我要淘汰家里旧的 Switch,天猫探物买了喷喷 3 限定版,打算今后出门背着斜挎包顺便带着出门玩。 今年的最期待最能给我生活动力就是就...

-
Vol.16 《铃芽之旅》中的爱情并不能让我共鸣
昨晚上去看了新海诚新的电影《铃芽之旅》,这也是我第一次在影院看新海诚的电影,非常喜欢《你的名字》,但后面的《天气之子》并不喜欢,男女主角突如其来的情感我确实不能理解,这一次也一样。铃芽跟草太是怎么互相吸引并且产生情愫的呢?开头到结尾都没有一个点让我感受到这两个人物直接有爱情火苗,以至于最后铃芽的行动...

-
Vol.15 来深圳第5次搬家
这周不仅工作很忙,周末搬家也很忙,博客水一期,分享一下我刚刚收拾好的狗窝。这一次我虽然还是合租,但现在是主卧,并且买了自己的冰箱,可以安心地做宅宅,完全没有出门的需求了,甚至连室友都不用再见啦。

-
Vol.14 说说我的数据仓库建设"最佳实践"
上周粗浅地聊了聊我对一个成熟数据仓库的设想,都是空谈理论,今天想记录一下一些可以实操的东西。同事经常提醒我,平时我时候容易抓不住重点,后续写东西尽量简介,能 50 个字说明白的东西,就不用 100 字。 开发规范 1. 统一开发脚本,离线任务建议通过 sh 脚本封装提交,将公共参数跟执行函数封装好,...

-
Vol.13 浅谈数据仓库DataWarehouse
数据仓库是什么 数据仓库是什么?根据 Google Cloud 的介绍: 数据仓库是一种企业系统,用于分析和报告来自多个来源的结构化和半结构化数据,例如销售终端交易、营销自动化、客户关系管理等。数据仓库适用于点对点分析以及自定义报告。数据仓库可以将当前数据和历史数据都存储在一个地方,旨在提供长期数据...
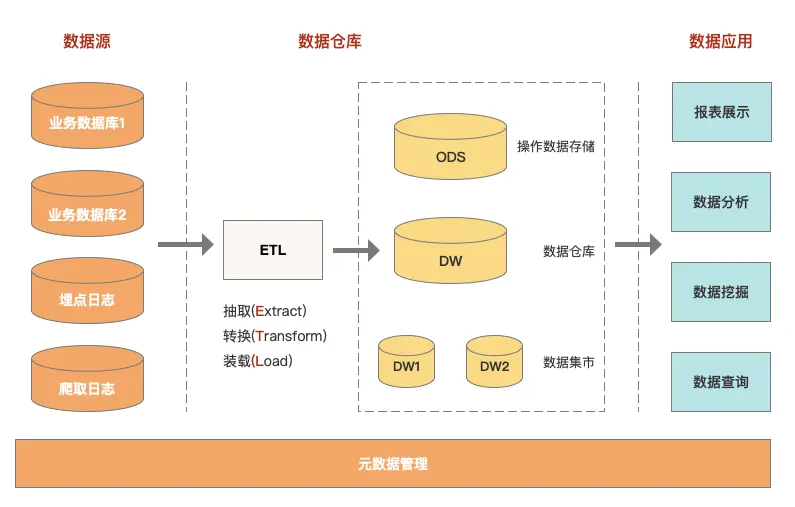
-
Vol.12 Kafka 核心工作原理小记
消息队列简介 概述 消息队列MQ用于实现两个系统或模块之间传递消息数据时, 实现数据缓存 功能 基于队列方式, 实现传递消息的数据缓存 应用场景 - 实时高性能高吞吐量高可靠的消息传递架构 - 大数据应用: 作为唯一的实时数据存储平台 - 实时数据采集: 生产写入Kafka - 数据数据处理: 消费...
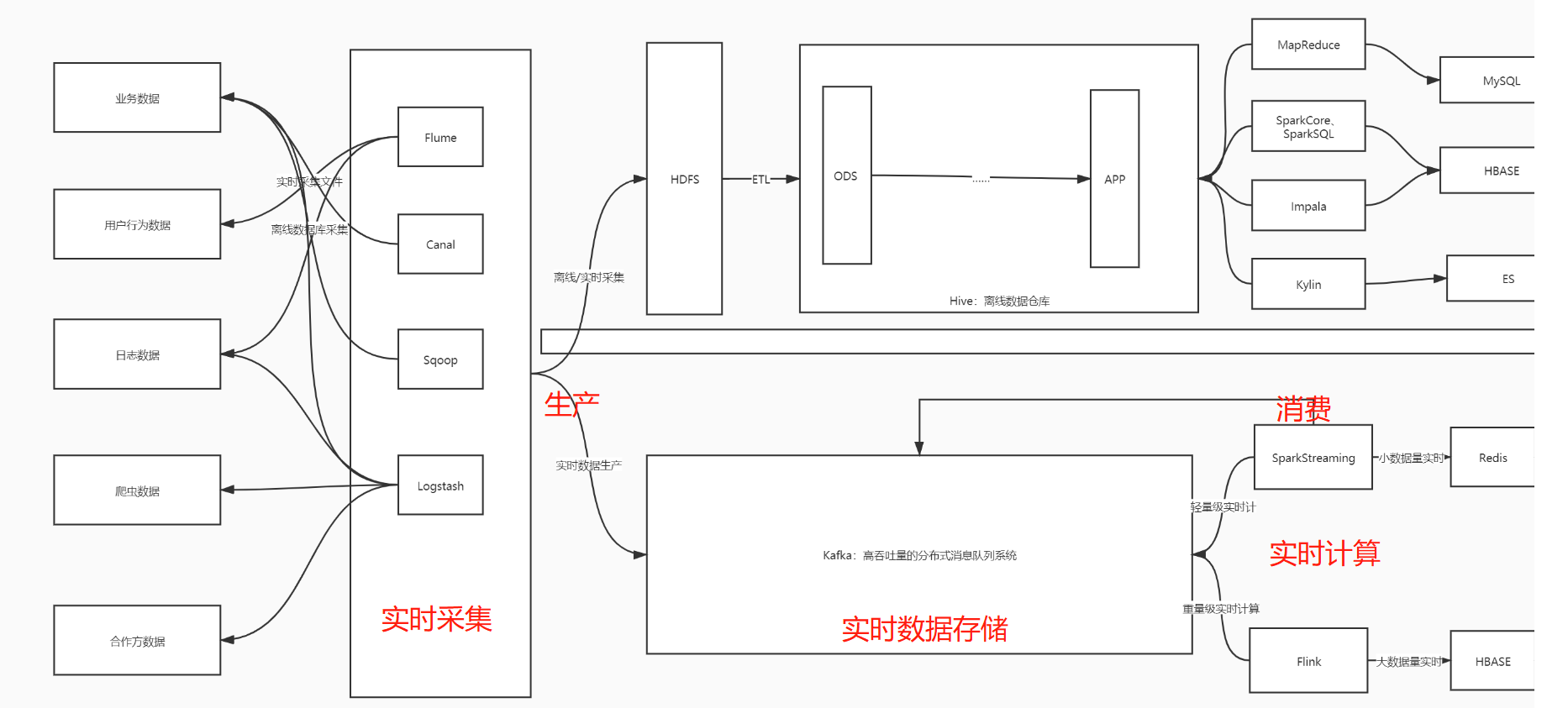
-
Vol.11 Hadoop核心工作原理小记
记录一下曾经学习 Hadoop 的笔记,温故知新,现在 Hadoop 已经到 3.x 版本,但是很多机制跟原理还是一致的。 HDFS分布式文件系统 设计目标 1、硬件故障是常态 2、HDFS上的应用与一般的应用不同,它们主要是以流式读取数据,更注重数据访问的高吞吐量 3、典型的HDFS文件大小是GB...

-
Vol.10 Spark核心工作原理小记
整理学习 Spark 相关知识的笔记,查缺补漏。不得不说整理的时候重新捡起了很多遗忘的知识,Scala 我也很久很久没有写了, 现在公司用的是 Pyspark ,后面也整理记录下 Pyspark 的相关笔记。 **Spark 组件的数据抽象和上下文对象** **SparkCore** - 数据抽象:...
-
Vol.09 M1款 MacBookPro 搭建 JupyterLab 数据分析环境
Python 用于数据分析的优势我就不多赘述,虽然当前基本不写 Python,但是我经常需要阅读 Python 代码,看别人写的数据处理逻辑,所以开始进一步学习 Pyspark 相关的知识。Jupyter 应该是学习 Python 数据分析最佳的工具了,趁着刚刚安装完,记录下自己环境配置跟常用的工具...

-
Vol.08 人性之恶,实难揣测----读《连城诀》
《连城诀》被评价作金庸的十五部武侠小说中最具现实主义、批判主义的一部,里面写尽了人性的阴暗面,金庸先生这部小说里要探讨的就是人性的肮脏罪恶。我是第二遍看这部小说了,读到万震山半夜梦游砌墙的情节,还是觉得瘆得慌。我总觉得金庸先生是以最恶意的角度去塑造书中的人物的,对于书中的各个人物我都是以消极负面地角...

-
Vol.07《流浪地球2》值得一看
今晚 8 点去电影院看 《流浪地球2》,看到机核电影场大家的评价,充满了期待。我对翻拍充满一种抵触情绪,即使拍得再好,可能都会破坏原著在我心目中的地位,因为文字的魅力在于你可以充分想象,一旦可视化之后可能会破坏心中美好的画面。因此,我喜欢《流浪地球》这样,基于原著背景重新创作的作品,既能有原著的魅力...

-
Vol.06 工作中使用MySQL遇到的几个小坑
MySQL 是工作当中经常使用到一个开源数据库,我当前工作主要使用 MySQL 作为报表存储数据库,以及承接数据提供给到下游业务使用。使用过程中遇到很多很多坑,都是小问题但是碰到了处理起来也是比较繁琐,特别记录一下。 分区问题 MySQL 数据库使用 InnoDB 引擎的时候是支持分区的,MySQL...
-
Vol.05 坚持运动一年让我的生活充满力量
本周超级猩猩出了 2022 年度运动报告,全年除了有一两个月因为疫情跟阳了门店停业,每周都坚持去超级猩猩上团课。全年锻炼 126 天,完成 161 次训练,上了 18 节早课,33 节晚课,上了 89 节 BC ,28 节 BJ 跟 23 节 RPM,全年上课时长 9410 分钟。感谢坚持努力的自己...

-
Vol.04 Hive / Spark 如何避免单节点全局排序?
最近因为经常对接模型算法,营销模型的一个应用场景是:按照模型打分取 TOPN 用户进行营销投放,由此就会产生一个全局排序的场景:**在用户量过亿的情况下,单点全局排序极其容易出现 OOM。**经历了几次线上事故之后,决心要彻底解决这个问题,跟同事请教了下,可以通过 **“加盐打散”** 来解决这个问...

-
Vol.03 数据开发当中如何验证数据结果准确性
前言说明 数据开发日常工作经常需要跟业务方核验数据,校验数据源、业务逻辑是否准确。这里的数据准确性跟 ETL 中的“精确一次性语义” 保证数据不丢失不重复不一样,说的是数据报表或者用户标签特征是否符合既定业务逻辑。 以我浅薄的经验来说,验证数据准确性主要从:明细数据逻辑验证、业务逻辑验证、白盒测试这...

-
Vol.02 推荐下今天发现的几个cheatsheet
今天发现了一个神奇的东西,名字叫 Cheat Sheet,就是各种语言工具的快捷键列表,这个对于我这样记不住各种东西的菜鸟帮助太大了,平时边用边记。 老年跟菜鸟的区别可能就是你对各种工具快捷键的熟悉程度。记录下常用的几个,纳入自己工作流当中。 - **Python 语言(有中文且也有其他工具语言的)...

-
Vol.01 什么是新怪谈—从《鼠王》开始说
频繁在机核的播客里被安利《鼠王》,忘记哪一期节目,介绍了《美国众神》的作者尼尔盖曼作品,就提到通俗奇幻小说的发展史。目前的这类奇幻类小说主要分三类:旧时代民间传说、克苏鲁世界、新怪谈,当然还有史蒂芬金自己独特的体系,不在讨论范围之内。当时就很好奇,为啥新怪谈叫新怪谈,新在哪里。最近机核上了鼠王有声书...
