AI 时代的数据仓库,不只是给 BI 报表供数,而是企业可信数据和 AI 应用的共同底座。
分类: 数据仓库
-
Vol.27 AI 时代的数据仓库应该如何建设

-
Vol.26 如何建设一套可执行的指标体系
指标体系不是指标清单,而是把业务目标、指标口径、数据模型和经营动作串起来的管理系统。

-
Vol.14 说说我的数据仓库建设"最佳实践"
上周粗浅地聊了聊我对一个成熟数据仓库的设想,都是空谈理论,今天想记录一下一些可以实操的东西。同事经常提醒我,平时我时候容易抓不住重点,后续写东西尽量简介,能 50 个字说明白的东西,就不用 100 字。 开发规范 1. 统一开发脚本,离线任务建议通过 sh 脚本封装提交,将公共参数跟执行函数封装好,...

-
Vol.13 浅谈数据仓库DataWarehouse
数据仓库是什么 数据仓库是什么?根据 Google Cloud 的介绍: 数据仓库是一种企业系统,用于分析和报告来自多个来源的结构化和半结构化数据,例如销售终端交易、营销自动化、客户关系管理等。数据仓库适用于点对点分析以及自定义报告。数据仓库可以将当前数据和历史数据都存储在一个地方,旨在提供长期数据...
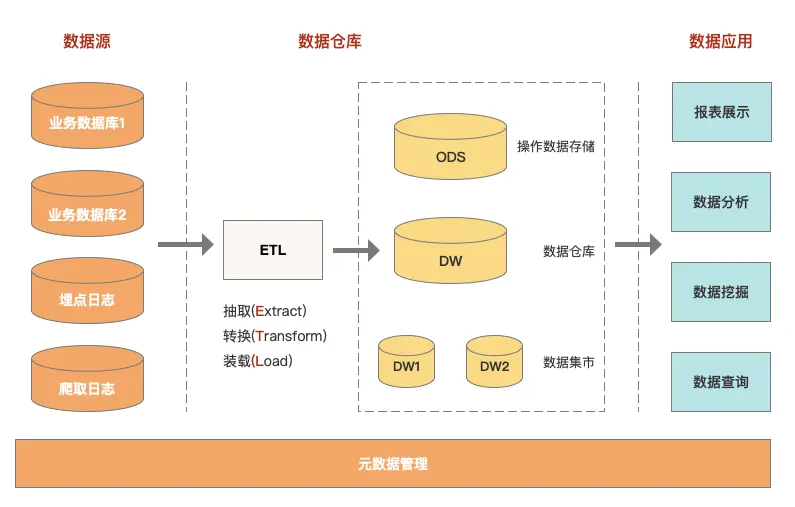
-
Vol.12 Kafka 核心工作原理小记
消息队列简介 概述 消息队列MQ用于实现两个系统或模块之间传递消息数据时, 实现数据缓存 功能 基于队列方式, 实现传递消息的数据缓存 应用场景 - 实时高性能高吞吐量高可靠的消息传递架构 - 大数据应用: 作为唯一的实时数据存储平台 - 实时数据采集: 生产写入Kafka - 数据数据处理: 消费...
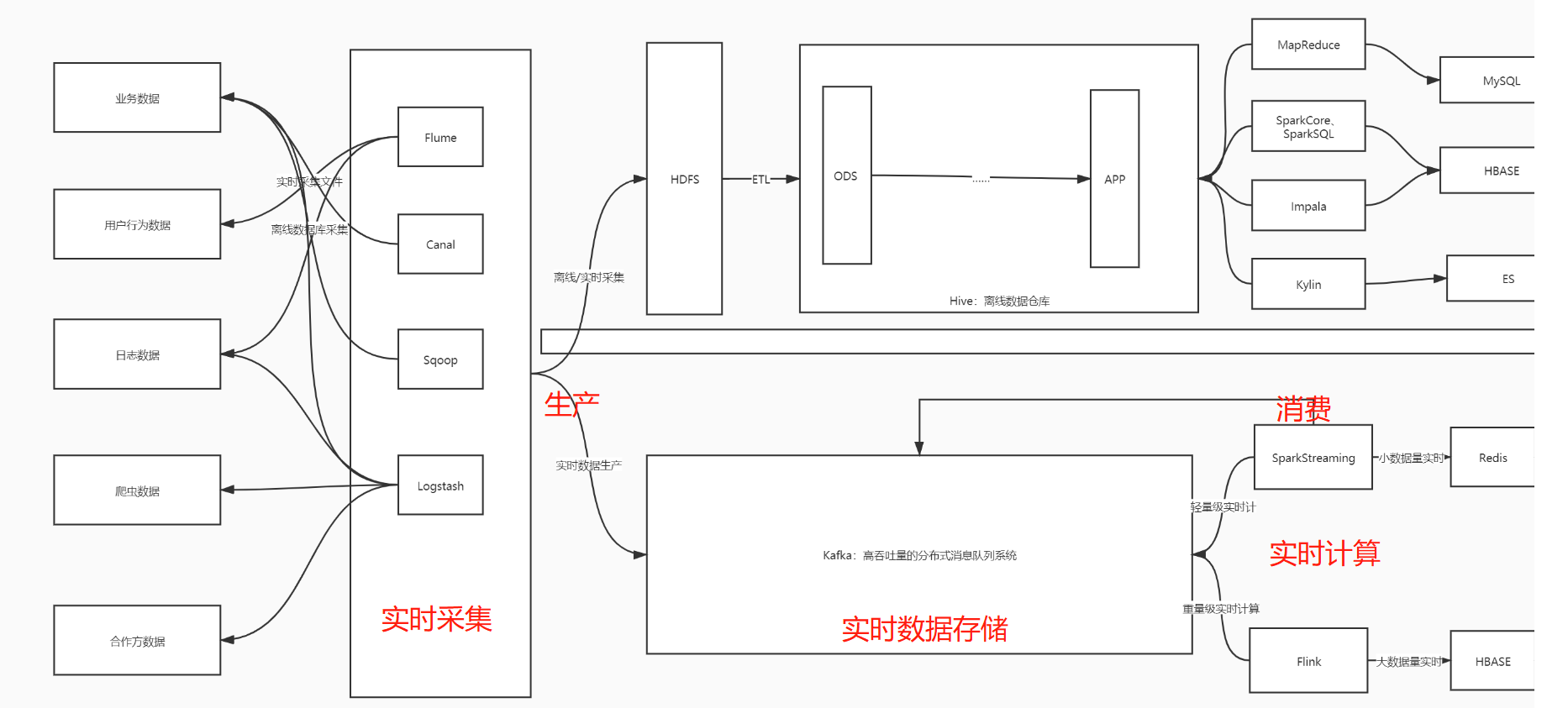
-
Vol.11 Hadoop核心工作原理小记
记录一下曾经学习 Hadoop 的笔记,温故知新,现在 Hadoop 已经到 3.x 版本,但是很多机制跟原理还是一致的。 HDFS分布式文件系统 设计目标 1、硬件故障是常态 2、HDFS上的应用与一般的应用不同,它们主要是以流式读取数据,更注重数据访问的高吞吐量 3、典型的HDFS文件大小是GB...

-
hive性能优化
基础优化 - Shuffle 阶段压缩 - hive的数据压缩 - Snappy - hive的数据存储格式 - ORC - TextFile - fetch抓取 - 本地模式 - join的优化 - 小表在前,小表放入缓冲区 - 谓词下推,先过滤再 join - SQL优化的方案 - 列裁剪 - ...

-
Hive数仓缓慢渐变维之拉链表
缓慢渐变维 主要是为了解决, 是否需要在数仓中维护历史变化的数据操作 注意:如果不维护一个数据的历史变化信息, 那么在进行数仓分析的时候, 是有可能对未来分析的结果产生影响 **实现缓慢维的3种方式** ```sql **SCD1** 对于历史变化的数据, 是进行维护操作, 直接进行覆盖即可 此种操...

-
Hive自动化建库建表
前言说明 项目数仓数据源太多,于是自己写了一个工具类,读取数据源的元数据信息,自动建库建表 以 MySQL 为例,代码如下。 HiveUtil ```java object HiveUtil { def main(args: Array[String]): Unit = { createHiveTa...

-
Sqoop自动化抽取数据与验证
前言说明 最近项目业务数据源多种多样,用 Sqoop 抽取数据到数仓是一个体力活,底层又是基于 MapReduce 执行的,速度感人,关键是还得做数据校验 于是想着自己写个工具类,和自动建表建库类似,自动读取数据源表和字段信息,创建对应脚本,扔到 DolphinScheduler 上自动跑就完事。 ...
