AI 时代的数据仓库,不只是给 BI 报表供数,而是企业可信数据和 AI 应用的共同底座。
所有文章
-
Vol.27 AI 时代的数据仓库应该如何建设

-
Vol.26 如何建设一套可执行的指标体系
指标体系不是指标清单,而是把业务目标、指标口径、数据模型和经营动作串起来的管理系统。

-
Vol.25 港版 iPhone 有什么特别的地方?
为什么我选择去香港买 iPhone 17 Pro?不仅是因为价格,更是为了原生 eSIM 体验。

-
Vol.24 hive 跟 clickhouse 的 TTL 机制
> 本文由 chatGPT 生成,可能存在一定错误,请读者自行甄别。 Hive和ClickHouse都支持TTL(Time-To-Live)机制,可以帮助用户自动管理表的生命周期,包括数据的删除和归档等操作。下面将分别介绍Hive和ClickHouse的TTL机制。 Hive的TTL机制 在Hive...

-
Vol.23 塞尔达就是天!
本周沉迷《塞尔达传说:王国之泪》,无心顾及其他,博客鸽了。 塞尔达就是天!永远能让我充满好奇心跟探索的欲望,让我重拾最本质的快乐,体验一段属于自己的冒险。能在有生之年玩到塞尔达太幸福了!

-
Vol.22 《大浴女》是复杂人性的真实记录
终于读完机核朋友推荐的铁凝的《大浴女》,看到结尾心情确实有些沉重。我很羡慕她们在最后可以勇敢又坦然地接纳自己,说出自己内心最深处伤痕。我经常跟别人说真正的放下就是微笑面对曾经恐惧逃避的事务,但我自己做不到,我还是无法接纳跟面对自己的原生家庭,我还在逃避。 书中对于人性的描写丝毫不忌讳,我真的感觉这才...

-
Vol.21 《灌篮高手》不是我的青春但依旧喜欢
假期第一天没有出门,想着再不做点什么浪费我美好的假期,于是看完《读库2301》之后临时约 22 点场,出门那一刻心情非常愉悦,今天焦虑抑郁愤怒的情绪消失殆尽。 这是我今年看过最喜欢的一部电影,比马里奥大电影还喜欢。看之前我还担心因为没有看过动画难以融入剧情,事实证明是我多虑了。湘北五虎每个人性格特点...

-
Vol.20 企业生产环境当中 spark 任务提交的几种方式
spark 任务提交 4 种方式 spark 任务提交的方式通常有 4 种:spark-shell、spark-sql 、Thriftserver 服务、spark-submit。 spark-shell spark-shell 是 Spark 自带的交互式 Shell 程序,方便用户进行交互式编程...

-
Vol.19 最好的同事这周离职了
这周坐我旁边的最好的同事离职了,工作 5 年,这个同事是我职场生涯当中关系最好的朋友。从我入职开始她就坐我旁边,手把手指导我度过新人期,可以说我在公司的所有知识跟技能都是她传授的。有些同事只是同事,有些是可以成为一生的朋友。刚刚到这家公司的时候,我是一个孤傲内向的钢铁直男,工作上粗心大意经常小错误,...

-
Vol.18 Redis 学习笔记
基本介绍 - 定义 - 基于内存的分布式的NoSQL数据库 - 设计 - 所有数据存储在内存中 - 内存数据同步磁盘,实现持久化 - 功能 - 提供高性能高并发的数据存储, 对外提供读写 - 主要用于数据库存储、数据缓存和消息中间件 - 特点 - 1.基于C语言开发,读写更快 - 2.基于内存实现数...

-
Vol.17 分享下定制的 splatoon3 铭牌跟斜跨包
非常喜欢,感觉有点羞耻怎么回事,在街上碰见我千万别打招呼 😂 铭牌跟鱼蛋徽章都是@贴牌小铺🦑冷店长,斜挎包是@tomtoc-official 定制的 为了塞尔达我要淘汰家里旧的 Switch,天猫探物买了喷喷 3 限定版,打算今后出门背着斜挎包顺便带着出门玩。 今年的最期待最能给我生活动力就是就...

-
Vol.16 《铃芽之旅》中的爱情并不能让我共鸣
昨晚上去看了新海诚新的电影《铃芽之旅》,这也是我第一次在影院看新海诚的电影,非常喜欢《你的名字》,但后面的《天气之子》并不喜欢,男女主角突如其来的情感我确实不能理解,这一次也一样。铃芽跟草太是怎么互相吸引并且产生情愫的呢?开头到结尾都没有一个点让我感受到这两个人物直接有爱情火苗,以至于最后铃芽的行动...

-
Vol.15 来深圳第5次搬家
这周不仅工作很忙,周末搬家也很忙,博客水一期,分享一下我刚刚收拾好的狗窝。这一次我虽然还是合租,但现在是主卧,并且买了自己的冰箱,可以安心地做宅宅,完全没有出门的需求了,甚至连室友都不用再见啦。

-
Vol.14 说说我的数据仓库建设"最佳实践"
上周粗浅地聊了聊我对一个成熟数据仓库的设想,都是空谈理论,今天想记录一下一些可以实操的东西。同事经常提醒我,平时我时候容易抓不住重点,后续写东西尽量简介,能 50 个字说明白的东西,就不用 100 字。 开发规范 1. 统一开发脚本,离线任务建议通过 sh 脚本封装提交,将公共参数跟执行函数封装好,...

-
Vol.13 浅谈数据仓库DataWarehouse
数据仓库是什么 数据仓库是什么?根据 Google Cloud 的介绍: 数据仓库是一种企业系统,用于分析和报告来自多个来源的结构化和半结构化数据,例如销售终端交易、营销自动化、客户关系管理等。数据仓库适用于点对点分析以及自定义报告。数据仓库可以将当前数据和历史数据都存储在一个地方,旨在提供长期数据...
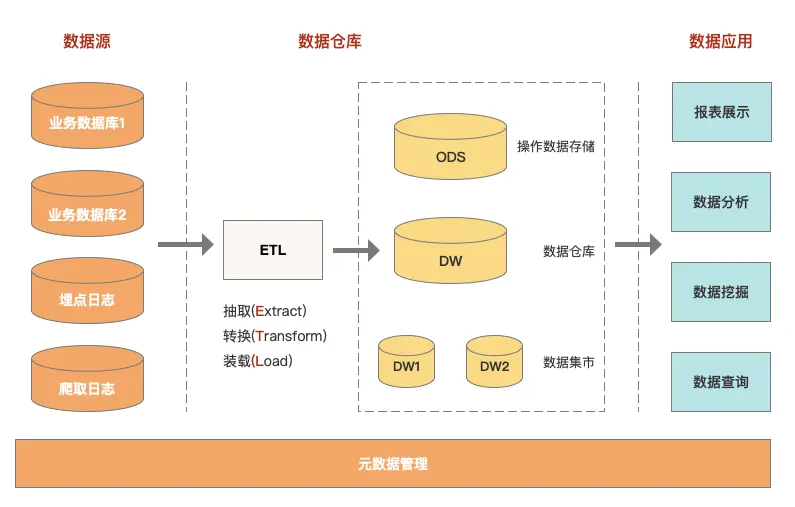
-
Vol.12 Kafka 核心工作原理小记
消息队列简介 概述 消息队列MQ用于实现两个系统或模块之间传递消息数据时, 实现数据缓存 功能 基于队列方式, 实现传递消息的数据缓存 应用场景 - 实时高性能高吞吐量高可靠的消息传递架构 - 大数据应用: 作为唯一的实时数据存储平台 - 实时数据采集: 生产写入Kafka - 数据数据处理: 消费...
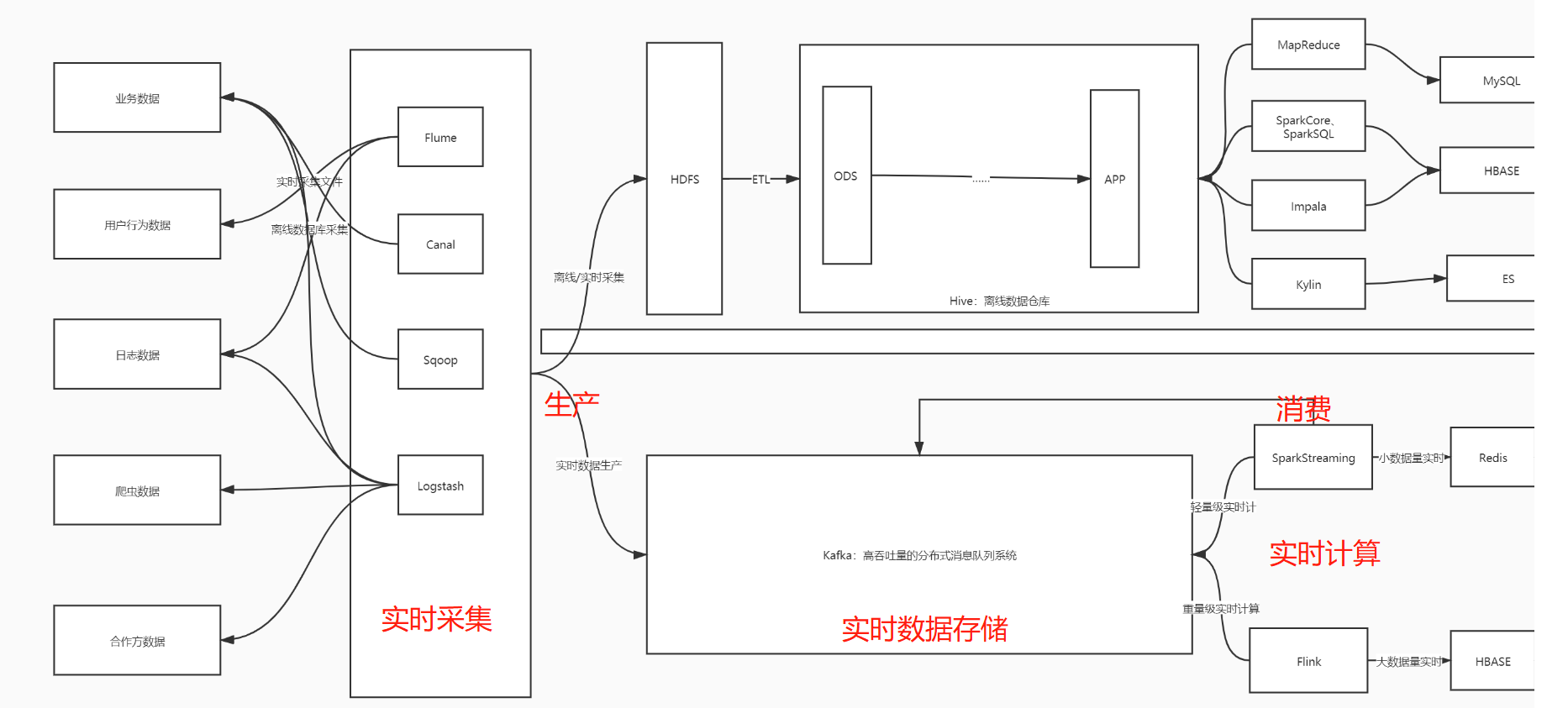
-
Vol.11 Hadoop核心工作原理小记
记录一下曾经学习 Hadoop 的笔记,温故知新,现在 Hadoop 已经到 3.x 版本,但是很多机制跟原理还是一致的。 HDFS分布式文件系统 设计目标 1、硬件故障是常态 2、HDFS上的应用与一般的应用不同,它们主要是以流式读取数据,更注重数据访问的高吞吐量 3、典型的HDFS文件大小是GB...

-
Vol.10 Spark核心工作原理小记
整理学习 Spark 相关知识的笔记,查缺补漏。不得不说整理的时候重新捡起了很多遗忘的知识,Scala 我也很久很久没有写了, 现在公司用的是 Pyspark ,后面也整理记录下 Pyspark 的相关笔记。 **Spark 组件的数据抽象和上下文对象** **SparkCore** - 数据抽象:...
-
Vol.09 M1款 MacBookPro 搭建 JupyterLab 数据分析环境
Python 用于数据分析的优势我就不多赘述,虽然当前基本不写 Python,但是我经常需要阅读 Python 代码,看别人写的数据处理逻辑,所以开始进一步学习 Pyspark 相关的知识。Jupyter 应该是学习 Python 数据分析最佳的工具了,趁着刚刚安装完,记录下自己环境配置跟常用的工具...

-
Vol.08 人性之恶,实难揣测----读《连城诀》
《连城诀》被评价作金庸的十五部武侠小说中最具现实主义、批判主义的一部,里面写尽了人性的阴暗面,金庸先生这部小说里要探讨的就是人性的肮脏罪恶。我是第二遍看这部小说了,读到万震山半夜梦游砌墙的情节,还是觉得瘆得慌。我总觉得金庸先生是以最恶意的角度去塑造书中的人物的,对于书中的各个人物我都是以消极负面地角...

-
Vol.07《流浪地球2》值得一看
今晚 8 点去电影院看 《流浪地球2》,看到机核电影场大家的评价,充满了期待。我对翻拍充满一种抵触情绪,即使拍得再好,可能都会破坏原著在我心目中的地位,因为文字的魅力在于你可以充分想象,一旦可视化之后可能会破坏心中美好的画面。因此,我喜欢《流浪地球》这样,基于原著背景重新创作的作品,既能有原著的魅力...

-
Vol.06 工作中使用MySQL遇到的几个小坑
MySQL 是工作当中经常使用到一个开源数据库,我当前工作主要使用 MySQL 作为报表存储数据库,以及承接数据提供给到下游业务使用。使用过程中遇到很多很多坑,都是小问题但是碰到了处理起来也是比较繁琐,特别记录一下。 分区问题 MySQL 数据库使用 InnoDB 引擎的时候是支持分区的,MySQL...
-
Vol.05 坚持运动一年让我的生活充满力量
本周超级猩猩出了 2022 年度运动报告,全年除了有一两个月因为疫情跟阳了门店停业,每周都坚持去超级猩猩上团课。全年锻炼 126 天,完成 161 次训练,上了 18 节早课,33 节晚课,上了 89 节 BC ,28 节 BJ 跟 23 节 RPM,全年上课时长 9410 分钟。感谢坚持努力的自己...

-
Vol.04 Hive / Spark 如何避免单节点全局排序?
最近因为经常对接模型算法,营销模型的一个应用场景是:按照模型打分取 TOPN 用户进行营销投放,由此就会产生一个全局排序的场景:**在用户量过亿的情况下,单点全局排序极其容易出现 OOM。**经历了几次线上事故之后,决心要彻底解决这个问题,跟同事请教了下,可以通过 **“加盐打散”** 来解决这个问...

-
Vol.03 数据开发当中如何验证数据结果准确性
前言说明 数据开发日常工作经常需要跟业务方核验数据,校验数据源、业务逻辑是否准确。这里的数据准确性跟 ETL 中的“精确一次性语义” 保证数据不丢失不重复不一样,说的是数据报表或者用户标签特征是否符合既定业务逻辑。 以我浅薄的经验来说,验证数据准确性主要从:明细数据逻辑验证、业务逻辑验证、白盒测试这...

-
Vol.02 推荐下今天发现的几个cheatsheet
今天发现了一个神奇的东西,名字叫 Cheat Sheet,就是各种语言工具的快捷键列表,这个对于我这样记不住各种东西的菜鸟帮助太大了,平时边用边记。 老年跟菜鸟的区别可能就是你对各种工具快捷键的熟悉程度。记录下常用的几个,纳入自己工作流当中。 - **Python 语言(有中文且也有其他工具语言的)...

-
Vol.01 什么是新怪谈—从《鼠王》开始说
频繁在机核的播客里被安利《鼠王》,忘记哪一期节目,介绍了《美国众神》的作者尼尔盖曼作品,就提到通俗奇幻小说的发展史。目前的这类奇幻类小说主要分三类:旧时代民间传说、克苏鲁世界、新怪谈,当然还有史蒂芬金自己独特的体系,不在讨论范围之内。当时就很好奇,为啥新怪谈叫新怪谈,新在哪里。最近机核上了鼠王有声书...

-
高效年轻人的7个办公习惯
偶然在即刻上看到飞书的 ZARA 分享了这篇小文章,高效年轻人的 7 个办公习惯,都是我目前所欠缺和需要学习的,至少我现在 ‘elevator list’ 就没有做到,经常是口头表达,而不是先准备好问题和资料。 1. 如果 leader 布置了一个任务,做到30%的时候先问老板方向对不对,不要憋大招...

-
SQLBoy日常工作技巧
入职新工作三周了,虽然还处理 SQLBoy 阶段,但是学习到了非常多小技巧,有必要记录一下,持续更新,避免遗忘。 - 规范需求记录,脚本备份,文档归类,代码片段,数字字典 - 封装公共参数和大数据脚本执行参数到脚本当中,执行脚本只需要引入变量 - 每一种 SQL 脚本方式封装一个方法,固定脚本执行格...

-
开发环境准备
最近换了 M1 MBP,新电脑开发环境需要从头部署,汇总一下我开发环境常用的工具吧。 环境支持 - 资源下载 $1 $1 - 安装说明 $1 $1 开发工具 - IDEA ```sql -- 插件 Cosy Java Coding Atom Material Icons PDF Viewer Rai...
-
SQL中的行转列和列转行
MySQL 的行转列 ```sql case when + group by + max/sum 函数 ``` MySQL 的列转行 ```sql select 指定语句 + union 拼接即可 union 去重 union all 不去重 FLink 中 union 不去重,相当于 SQL中的 ...

-
Awk和Shell
awk 格式 - `awk [选项参数] 'script' var=value file(s)` - 基本语法 - $0 代表整个文本行 - $1 代表文本行中的第 1 个数据字段 - printf 打印输出 - 默认每行按空格或TAB分割,使用$n来获取段号 段连接符OFS - `awk '{OF...

-
hive性能优化
基础优化 - Shuffle 阶段压缩 - hive的数据压缩 - Snappy - hive的数据存储格式 - ORC - TextFile - fetch抓取 - 本地模式 - join的优化 - 小表在前,小表放入缓冲区 - 谓词下推,先过滤再 join - SQL优化的方案 - 列裁剪 - ...

-
Hbase 无法删除表问题及解决办法
问题描述 - 正常删除表格的方法 ```bash 禁用表 disable "TRIPDB:trip_sample" 删除表 drop "TRIPDB:trip_sample" ``` 但是操作过程中出现如下的问题 - 已经禁用表 ```bash hbase(main):005:0> disable ...

-
Hive数仓缓慢渐变维之拉链表
缓慢渐变维 主要是为了解决, 是否需要在数仓中维护历史变化的数据操作 注意:如果不维护一个数据的历史变化信息, 那么在进行数仓分析的时候, 是有可能对未来分析的结果产生影响 **实现缓慢维的3种方式** ```sql **SCD1** 对于历史变化的数据, 是进行维护操作, 直接进行覆盖即可 此种操...

-
牛客网SQL练习总结
补充知识 补充知识整理 ```sql 1.一张表可以多次被引用使用 2.筛选条件包含某个值, 这个值可以通过子查询求出, 再通过 where 条件判断 3.子查询没有符合要求的条件会直接返回 null 4.insert ignore into 相当于 replace 5.创建视图格式: create...

-
Redis常见面试题
前言说明 学习和整理 Redis 相关的知识当中,这里汇总了一下经常被问到的 Redis 面试题 Redis 的八股无外乎这三个:缓存穿透、缓存击穿、缓存雪崩。 分片集群问题 1.Redis的多数据机制了解多少 ```sql 1.Redis支持多个数据库,单机模式下有从db0到db15, 数据库之间...

-
管理配置文件的工具:Commons Configuration
一般读取配置文件,或者说集群环境传参的方式有如下几种: 1、Main 程序留出参数入口,通过 args 接收参数,运行 jar 的时候传入参数 2、将配置文件放入 resources ,通过类加载器获取参数文件,或者创建专门工具类读取resources 中的配置文件信息 这两种方法各有优缺点,第一种...

-
更好的日志框架:logback
基本介绍 Logback 是由 log4j 创始人设计的另一个开源日志组件 官方网站: $1 它分为下面下个模块: - logback-core:其它两个模块的基础模块 - logback-classic:它是 log4j 的一个改良版本,同时它完整实现了 slf4j API使你可以很方便地更换成其...

-
Apache Spark:分布式并行计算框架(三)
Spark on Hive > 面试题:`spark on hive和hive on spark`区别???? > 典型**基于Spark和Hive离线数仓**架构技术图,简易版本: ``` 1、SparkSQL分析数据 2、Hive 管理元数据 | Spark on Hive 架构,离线数据仓库分...

-
Apache Spark:分布式并行计算框架(二)
1、Spark 有哪些优化 第一、公共优化 > 1、序列化(`Serialization`) ``` Spark中默认序列化方式: Java 序列化(Java serialization) 要求数据类型必须实现序列化接口Serializable,比如HBase数据库读取数据时,封装到Result 设...
-
Apache Spark:分布式并行计算框架(一)
0、前言说明 整理和汇总一下 Spark 容易混淆的概念和理论。 1、Spark 框架概念 ``` Apache Spark™ is a unified analytics engine for large-scale data processing. 1、unified 统一 Spark 框架可以...
-
Hive自动化建库建表
前言说明 项目数仓数据源太多,于是自己写了一个工具类,读取数据源的元数据信息,自动建库建表 以 MySQL 为例,代码如下。 HiveUtil ```java object HiveUtil { def main(args: Array[String]): Unit = { createHiveTa...

-
Sqoop自动化抽取数据与验证
前言说明 最近项目业务数据源多种多样,用 Sqoop 抽取数据到数仓是一个体力活,底层又是基于 MapReduce 执行的,速度感人,关键是还得做数据校验 于是想着自己写个工具类,和自动建表建库类似,自动读取数据源表和字段信息,创建对应脚本,扔到 DolphinScheduler 上自动跑就完事。 ...

-
多表连接过滤条件在 on 和 where 的区别
前言介绍 最近项目中的小坑,记录一下。 数据准备 ```sql create table student ( sid int primary key not null , cid int null, t_sex varchar(20) null ) comment '学生表'; create tab...
